Tiny transparent image files have played a significant role in the history of the Web. Digital folklorist, Olia Lialina has done some great work exploring the presence of spacer GIFs in the Geocities web archive and on how those GIFs persisted in some cases beyond the deletion of geocities. These invisible files have a story to tell, and I think exploring there presence and traces in web archives can end up illustrating some ideas for modes of researching in web archives.
Exhibiting the Invisible
Here is a picture of an exhibition Olia mounted of various historically significant transparent GIFs.
They are all hot linked from their original URLs. As a result, the broken image symbol is the thing that alerts us to the presence of the one’s that are still alive and out there.
Here is how Olia explained their role in an interview:
I remember, everybody who made pages in the 90s had cgif, maybe it was called clear gif, some people would call it zero-dot-gif, but it was this transparent one that would help you to make layouts, and now we can say that this, we found, we can maybe try to build now something out of this invisible gif, just implement it in our work, whatever it is, and make it in our own pages, this to prolong the life of Geocities.
In an effort to get outside screen essentialism I’ve been a bit smitten with the idea of looking at things like cryptographic hashes to show how two things that look the same are, at a lower level, not the same. So I did a bit of experimenting with
Was there an Original Transparent GIF?
So I generated SHA-1 hashes for all of the .gifs that Olia shared in her online exhibition to see the extent to which some of them are actually the same original file with different names. (It is also possible that they were generated through exactly the same process, but I imagine that is unlikely.) I’ve got a picture of it below, but here is a link to the spreadsheet.

I’ve colored in the hashes that are the same as each other. The result is to see that there aren’t really 10 different files here, instead three of these GIFs are identical. Interestingly we can also see which of these has been present and associated with the provided URLs the longest in the Internet Archive. So, the two geocities files there predate their crawl of google’s first clear.gif.
What was the break out transparent GIF?
Andy Jackson from the British Library was generous enough to take a look for these SHA values in the UK Web archive. He published the data and the scripts to visualize it online. One of them, cleardot.gif, appears in the UK web archive over a million times!
It’s likely that we are seeing a lot of the underlying crawl dynamics here as much as we are seeing trends in the history of the GIFs. With that said, we can see the scale at which these GIFS appear around the UK web.
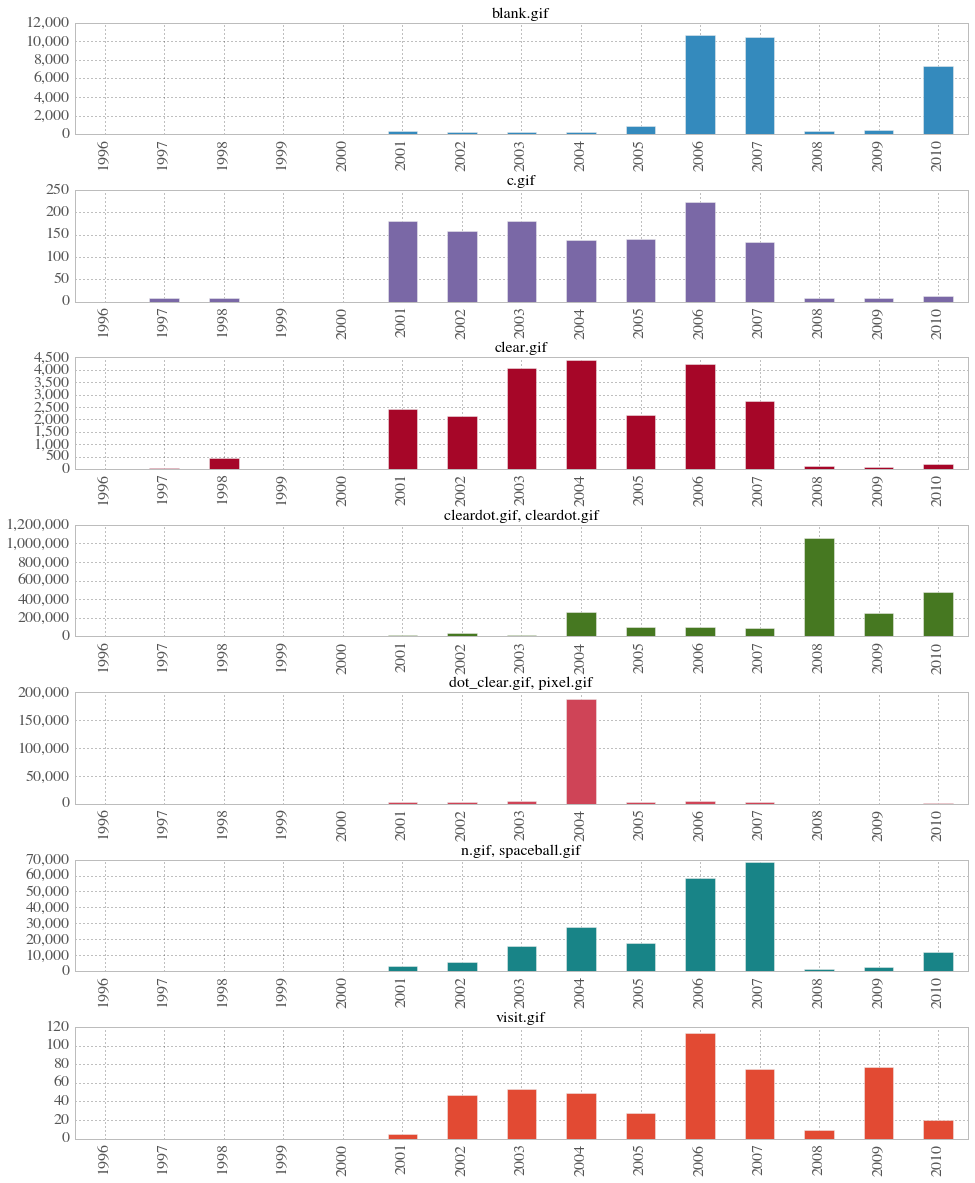
From the data we learn of three extant examples of GIFs in the archive dating from 1996. These include 2 instances of Blank.gif, 3 instances of pixel.gif and 46 instances of spaceball.gif. So, there is at least in terms of what the UK Web archive collected, spaceball.gif was the early break out hit.
Transparent GIF trends
The trends over time (pictured below) are interesting in their own right. I’m curious what folks think we learn from this?
Look at the scale on cleardot.gif. In 2008 more than a million instances of that GIF appear in the UK Web archive. At the same time, why do most of the other transparent GIFs all but disappear in 2008?What do we make of the resurgence of blank.gif in 2010? What is up with the massive spike of pixel.gif in 2004?
Interestingly, each one of these exists in the UK webarchive by 1997. Which makes sense based on where they come from in Olia’s research. Which opens the question of when and how they made their ways across the web. They were all there, for the most part at the beginning, so what circumstances led one to appear so often and the others not? Why do they all but disappear from the archive in 1999 and 2000?
If we were to zero in on that early year we could well pinpoint the URL that each of these images first appeared at in the archive and they day they first appeared.
The Shape of the Trend, The Shape of history and the Scope of the Crawl
What is it that we are actually mapping out here? That is, where are we seeing the history and spread of these files and where are we seeing the history of decisions about what is crawled and how those crawls are scoped? To that end, the note Andy sent me after doing the check is important context. He suspects that some of the dramatic drop offs in the charts may be the result of scoping decisions to exclude them from the crawls at different points in time.
It is entirely possible that the lack of any of these for the two-year period (1999 and 2000) reflect decisions to exclude these files from crawls. Along with that, Andy brought up another interesting point, that likely the reason many of these GIFS show up so often is that aside from being used for spacing and layout they were also used to track hits as “web bugs“. Which opens an interesting question, does the massive increase in the presence of these files around 2001 illustrate the beginning of that trend? To that end, here is an article from July of 2000 on the phenomena.
Counting Things You See Straight Through
I don’t know what this all means, but I think it opens up some interesting questions and comes with some implications. Who would have thought a bunch of tiny files that you see straight through would have so much to teach us. Here is my first run at some implications.
- Lots of Potential in Exploring Web Archives by Hash Value: We learn a lot when we see the traces of these images in the archives over time. I think it would be neat to see other exploration of hashes as a way to study web archives and I also think it might be interesting to see this become something that web archives consider as a way of providing access to their collections. When we end up knowing that two URLs held identical files at a particular date we could start to track and trace the replication and movement of information. Importantly, this is all derivative information about the content. So even in a situation where you can’t offer global access to the content itself you could very well provide the hashes for this kind of work.
- Essential Need to Document Crawling Practices & for Looking for Traces of Crawling Practices: Andy’s point about changes in scoping the crawls dramatically change the way that one interprets the data. With that said, the drop off to 0 across the board in 1999 and 2000 is likely also a good thing to file away for web archive researchers. Something that dramatic should suggest considering if some collecting process factor is coming through. This both underscores the value of creating scope and content notes and keeping logs and all kinds of other records of crawling practice and gestures toward the need to develop methods and techniques for interpreting web archives that respect the nature of web archiving practice.
- The Value of Multiple Archives: Given that crawling practices are going to be different in different archives there is a ton of value to having a lot of different archives. If we looked at trends for these files in other web archives we would start to see the trends that cross different approaches to crawling and get closer to understanding what parts of what we are seeing are part of the crawler and the collection and what are part of the web as it was.
- The Value of Records of Multiple Copies: The trends in the appearance of these files opens up all kinds of questions. Think about similar approaches to all kinds of other files. That is, trends in identical copies of files are themselves telling about the movement, dissemination, and popularity of practices and approaches. So there is informational content in the files, but the history of the appearance of a given file in a given place also comes with a lot of potential informational value.
- Hashes are Still Just One Way of Characterizing: While hashes are exciting, it’s important to remember that there are many other ways to characterize similarity. It might be interesting to just look for .gif files that are really tiny to see how many other SHA values we can identify for other transparent GIFs. When one moves further into hash based approaches to studying files it’s going to be important to remember that minor changes in a file are going to give it a totally new hash. So it will still be interesting to continue exploring ways of suggesting that two images are likely versions of the same thing through different methods of characterizing the files and then exploring how to store that information to aid in research and discovery.
What do you think?
I would love to hear from other folks about what you think these trends suggest. Also, if folks want to do their own explorations of some of this stuff please share results and thoughts on that back here in the comments too.

{kind=link}
{kind=link}
{kind=link}
Leave a comment