Systems and tools for crowdsourcing transcription and description proliferate, and libraries and archives are getting increasingly serious about collectively figuring out how to let others describe and transcribe their stuff. At the same time, there continues to be a lot of interest in the potential for linked open data in libraries archives and museums. I thought I would take a few minutes to try and sketch out a way that I think these things could fit together a bit.
I’ve been increasingly thinking it would be really neat if we could come up with some lightweight conventions for anyone anywhere to describe an object that lives somewhere else. At this point, things like the Open Annotation Collaboration presumably provide a robust grammar to actually get into markup and whatnot if folks wanted to really blow it out, but I think there is likely some very basic things we could just do to try and kick off an ecosystem for letting anyone mint URLs that have descriptive metadata that describe objects that live at other URLs.
My hope in this, is that instead of everyone building or standing up their own systems, we could have a few different hubs and places across the web where people describe, transcribe and annotate that could then be woven back into the metadata records associated with digital objects at their home institutions. In some ways this is really the basic set of promises and aspirations that Linked Open Data is intended to help with. Here I am just intending to try an think through how this might fit together in a potential use case.
A Linked Open Crowdsourcing Description Thought Experiment
With a few tweaks, we are actually very close to having the ability to connect the dots between one situation in which people further describe archival materials (in this case to create bibliographies) that could provide enhanced metadata back to a repository. I’ll talk through how a connection might be forged between Zotero and one online collection, but I think the principles here are generic enough that if folks just agreed on some conventions we could do some really cool stuff.
The Clara Barton papers are digitized in full, but in keeping with archival practice, they are not described at the item level. In this case, the collection has folder level metadata. So since it’s items all the way down in a sense, the folders are the items.
As a result, you get things that look like this, Clara Barton Papers: Miscellany, 1856-1957; Barton (Clara) Memorial Association; Resolutions and statements, 1916, undated. This is great. I am always thrilled to see folks step back from feeling like they need item level description to make materials available on the web. Describe to whatever level you can and make it accessible.
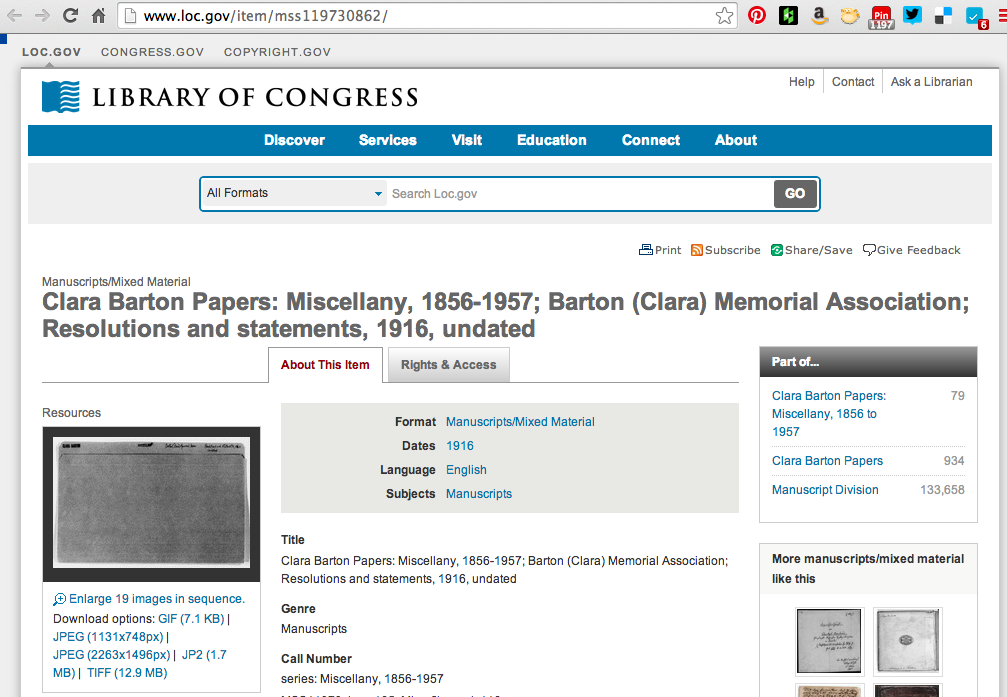
With that said, I’m sure there are people who are willing to pitch in and make some item level metadata for the stuff in that folder. Beyond that, if a scholar is ever going to actually use something in that folder and cite it in a book or a paper they are going to have to create item level description. Wouldn’t it be great if there was a generic way for the item level description that happens as a matter of course to put a footnote in an article or a book could be leveraged and reused?
Scholars DIY Item Level Description in Zotero
Everyday, a bunch of scholars key in item level description for materials in reference managers like Zotero. To that end, I’ll briefly talk through what would happen if someone wants to capture and cite something from the Clara Barton Papers in Zotero. Because there is some basic embedded metadata in that page, if you click the little icon by the URL you get that initial data, which you can then edit. You can also then directly save the page images into your personal Zotero library.
So you can see what that would look like below. I started out by saving the metadata that was there, I logged the URL that the actual item starts at inside the folder, changed it from a web page to a document, keyed in the title and the author of the document. I also saved the 2 actual images that are associated with the two images from the 19 images that are actually part of the item I am working with as attachments to my Zotero item.
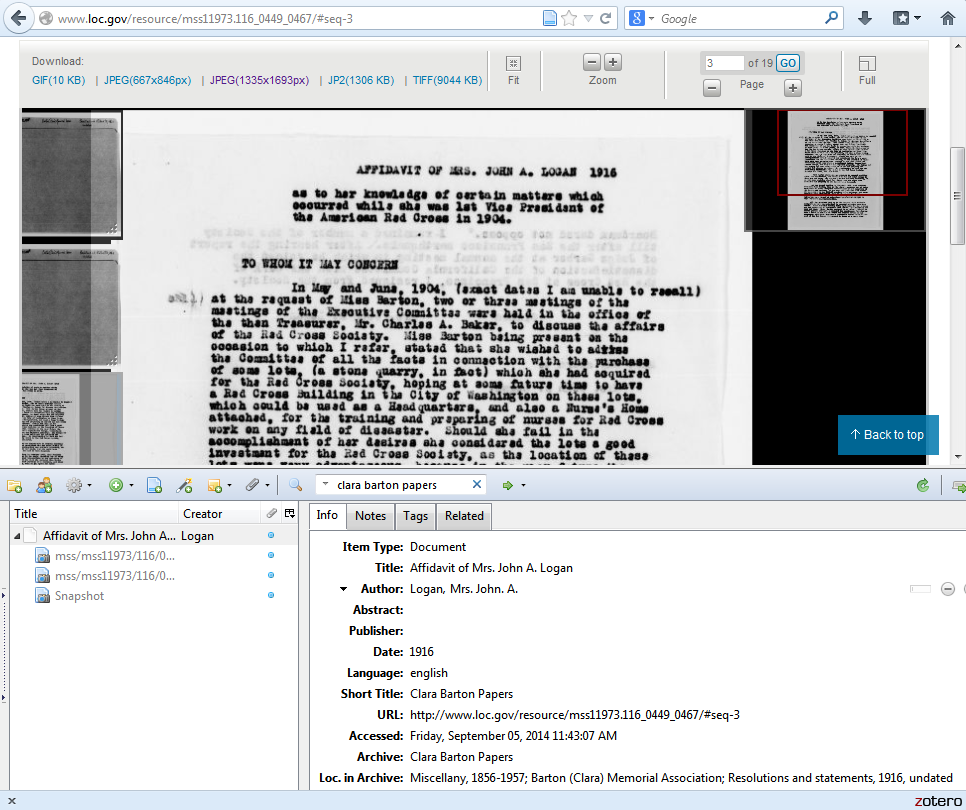
So, now I can go ahead and drag and drop myself a citation. Here is what that looks like. This is what I could put in my paper or wherever.
Now, wouldn’t it be great if there was a way for Zotero to ping, or do some kind of track back to the repository to notify folks that there is potentially a description of this resource that now exists in Zotero. That is, if I could ask Zotero’s API to see every public item they have that is associated with a loc.gov URL. In particular, every item that someone actually went through the trouble to tweak and revise as opposed to the things that are just the default information that came out to begin with.
Connecting Back from the Zotero instance of the Item
At this point, I added in descriptive information, and because I have the two actual image files, I also know that the information I have refers directly to mss/mss11973/116/0400/0451.jp2 and mss/mss11973/116/0400/0452.jp2. So, from this data we have enough information to actually create a sub-record for 2 of the 19 images in that folder.
Because I have a public Zotero library, anyone can actually go and see the Item level record I created for those 2 images from the Clara Barton Papers. You can find it here https://www.zotero.org/tjowens/items/itemKey/IHKBH5WQ/. In this case, the URL tells you a lot about what this is off the bat. It’s an item record from Zotero.org user tjowens and it has a persistent arbitrary item ID in tjowens’ library (IHKBH5WQ). Right that page could track back to the URL it is associated with, or even something simpler than that, just a token in the link that a repository owner could look for in their HTTP referrer logs as an indicator that there is some data out there at some URL that describes data at a URL that the repository has minted. So for instance, just stick ?=DescribesThis or something on the URL, like http://www.loc.gov/resource/mss11973.116_0449_0467/#seq-3?=DescribesThis . Then tell folks who run online collections to go and check out their referrer traffic for any incoming links that have ?DescribesThis in them. From there, it would be relatively trivial to review the incoming links from logs and decide if any of them were worth pulling over to add in as added value of descriptive metadata.
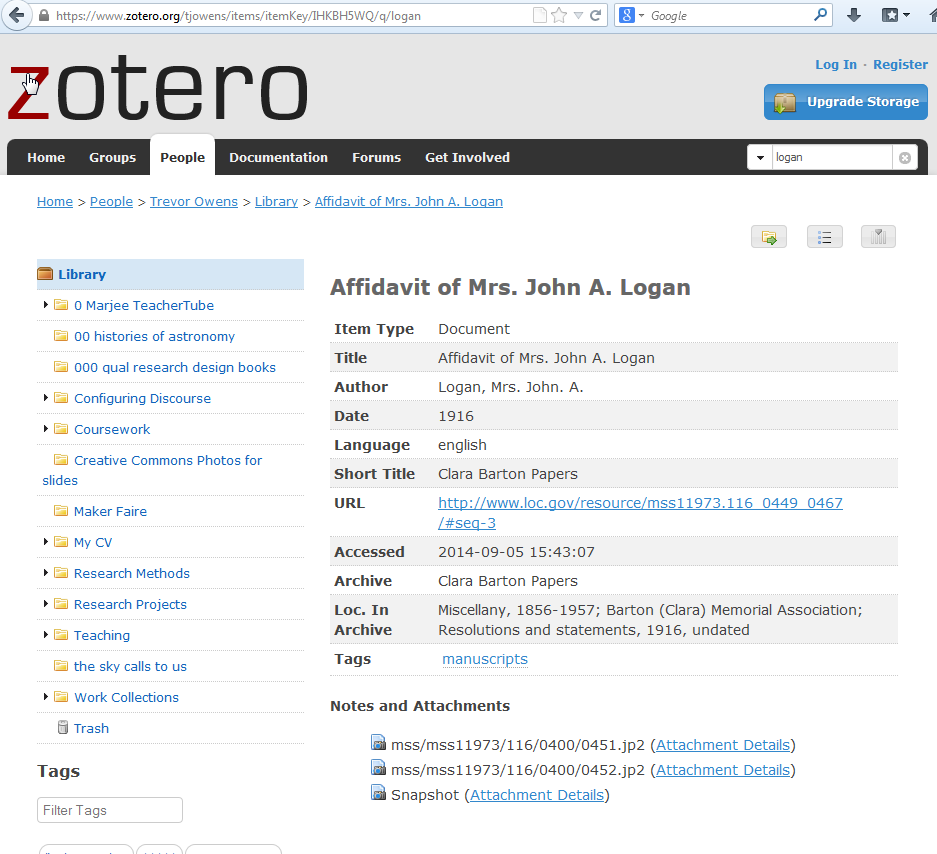
Aside from just having this nice looking page about my item, the Zotero API means that it’s trivial to get the data from this marked up in a number of different formats. For instance, you can find the JSON of this metadata at https://api.zotero.org/users/358/items/IHKBH5WQ?format=json

So, if someone back at the repository liked what they saw here, they could just decide to save a copy of this record, and then ingest it or integrated it with the existing records in your index through an ETL process.
What I find particularly cool about this on a technical level, is that it becomes trivial to retain the provenance of the record. That is, an organization could say “description according to Zotero user tjowens” and link out to where it shows up in my Zotero library. This has the triple value of 1) giving credit where credit is do and 2) offering a statement of caveat emptor regarding the accuracy of the record (That is, it’s not minted in the authority of the institution but instead the description of a particular individual) and 3) providing a link out to someone’s Zotero library that likely could enable discovery or relate materials from other institutions.
Linked Open Crowdsourced Description
The point of that story isn’t so much about Zotero and the Clara Barton Papers, but more about how with a little bit of work, those two platforms could better link to each other in a way that the repository could potentially benefit from the description of it’s materials that happens elsewhere. If a repo could just get a sense of what people are describing of it’s materials, they could start playing around with ways to link to, harvest, and integrate that metadata. From there, organizations could likely move away from building their own platforms to enable users to describe or transcribe materials and instead start promoting a range of third party platforms that simply enable users to create and mint descriptions of materials.
