
I had the privilege of participating in The Radcliffe Workshop on Technology and Archival Processing a few weeks back. I was thrilled to be on a great panel with some early career historians and Maureen Callahan.
Maureen posted her talk The Value of Archival Description Considered online. I encourage you to read it. It’s super good. I was thrilled to find that, I think we are on nearly the exact same wavelength about the future of the finding aid.
There was a nice write up about the event in the Harvard Gazette. I won’t deny that I may be “a millennial who displayed affection for the word “awesome” during the panel.” However, there are some clarifications I should make. I did not talk about obeying “cyborg overlords”, or a “mechanized shirt of armor.” In sharing some of the points of my talk I thought it would be good to focus in particular on parts of these clarifications. I think getting the language right about the future of our relationships with software is important, so here goes.
Maureen Welcomed the Robot Overloards, but with good reason!
Maureen had a few great lines in her talk (again, if you haven’t read it go do so now). One of those lines was her take on a Simpsons quote, “I for one welcome our robot overlords.” She went on to explain, in an even better line, “I don’t think that archivists are just secretaries for dead people, and I welcome as much automation as we can get for this kind of direct representation of what the records tell us about themselves.” I love this quote. When I was sitting there listening to her I was nodding so much. This is exactly the sentiment I wanted to get at.
The future of digital tools for archives is not replacing the work. It is automating the parts of the work that are not the intellectual labor. Along with that, the future of these tools is largely about taking advantage of the affordances in the nature, structure and order of digital media which give us considerable power to scale up our actions and interventions in the record.
I took the key theme from her pitch to be something like, let the algorithms and digital tools do the repetitive and less intellectual labor of the archivist, and get the archivist more involved in the intellectual labor of the archives. Specifically, in better contextualizing, explaining and describing the provenance of collections and making the decisions that require the kind of sophisticated judgment that people have and exercise. Without knowing where she was going, I touched on several similar themes in my talk. Ideas and visions of the labor relationship between the archivist of the future and the algorithms, scripts and tools that work for her and do her bidding.

We get to wear the robots!

So we don’t want the dark vision of the robot master. We certainly don’t want the machines turn us into into the Borg or Cybermen, who lose their souls as they are taken over by the emotionless machine.
My vision for the future of the archivist using digital tools is less Borg and more Exo-suit.
The idea of mecha or exo-suits, illustrates a vision of technology that extends the capabilities of it’s user. That is, the kinds of tools I think we need going forward are exactly the sort of thing that Maureen was talking about. Things that let us automate a range of processes and actions.
We need tools that let us quickly work across massive amounts of items and objects by extending and amplify the seasoned judgment, ethics, wisdom, and expertise of the archivist-in-the-machine.
Fondz as a Tool Thought Experiment for Automation
I was recently working with some archivists who had a project where they had nearly 400 floppy disks containing drafts of letters, books, essays, etc. In short, digital copies of all the kinds of things you find in a collection of someone’s personal papers. I hope to write about that project in more detail in the future, but for now I just wanted to talk a little about a tool that got cooked up in the process. So, what can you do with some 19,000 documents like this? Now, you can learn a ton about a set of digital files by extracting and identifying them in automated processes. That is, what kinds of files they are, their file names, size, etc. It’s really useful data! However, in most cases, this is not at all the data that a researcher or other user who might work with the collection would want. Inevitably, users want to know where information related to x, y, or z is in a collection. That is, users care about topics and subjects, and the kinds of tools most of us have at hand don’t really do much with that.

To this end, I asked my colleague Ed Summers a while back if it would be possible to strip out all the text from these documents, topic model it, and then use the topic models as an interface to the documents. In response, he cooked up a tool called Fondz.
For those unfamiliar, the MAchine Learning for LanguagE Toolkit (MALLET) describes topic modeling as follows. “Topic models provide a simple way to analyze large volumes of unlabeled text. A “topic” consists of a cluster of words that frequently occur together. Using contextual clues, topic models can connect words with similar meanings and distinguish between uses of words with multiple meanings.” In this case a tool like MALLET can quickly look across a large collection of texts and identify topical clusters of terms that appear near each other.

I really like how Ed describes Fondz, so I’ll share it here.
fondz is a command line tool for auto-generating an “archival description” for a set of born digital content found in a bag or series of bags. The name fondz was borrowed from a humorous take on the archival principle of provenance or respect des fonds. fondz works best if you point it at a collection of content that has some thematic unity, such as a collection associated with an individual, family or organization.
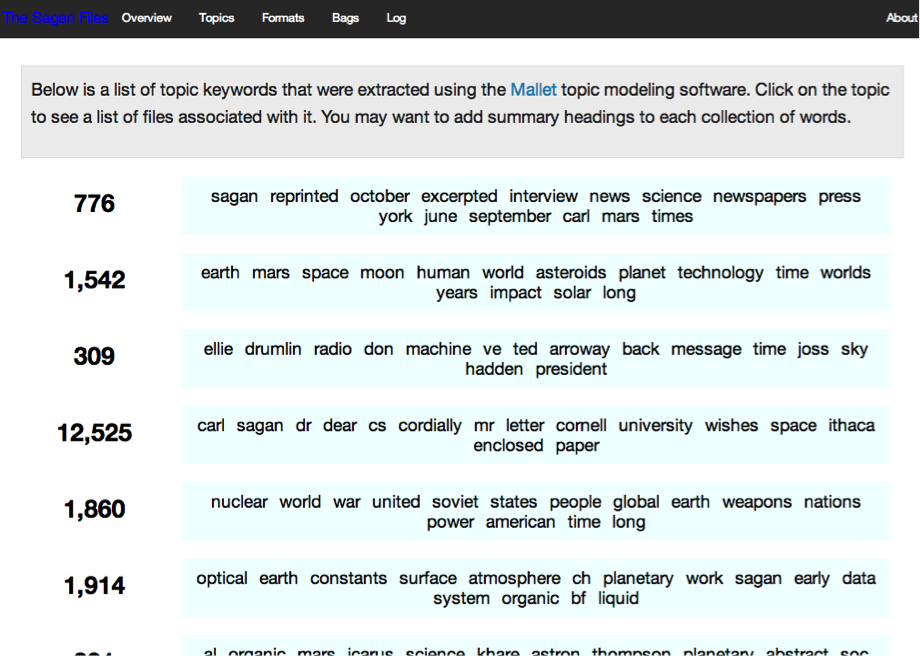
Above, you can see an example of Fondz in use. This is a list of the topics that Mallet identified, in each case you see the number of documents associated with the topic on the left and in the blue box you see the terms which Mallet has identified as being associated with that topic. That first one, with 776 documents, ends up being a cluster of files versions of biographical notes and CVs, the third one, with 309 topics, is materials related to a novel and a film adaptation of that novel. Mallet doesn’t know what those topics are. It just sees clusters of terms. Based on my knowledge of the collection, I’m able to identify and name those clusters.
The result of all this is a topical point of entry to explore 19,000 digital files from hundreds of floppies. It would work just as well for OCR’ed text from recent typed and printed text. I can’t show it to you in action because I don’t have a test collection that I can broadly share. (Note, anyone who has a similar collection they can broadly share contact me about it) But take my word for it. You click on one of those topics and you see a list of all the files that are associated with it and if you click on the name of one of those files you end up seeing an HTML representation of all the text inside that file. Alongside this, a future idea would be to integrate tools that do things like Named Entity Extraction (NER) to identify strings of text that look like names of people, places and locations. Indeed, there are already attempts to use NER for disambiguation in cultural heritage collections. What is particularly important here is not that we build tools that do this “right” but that we find and use tools that make things that are “good enough” in that they are useful in helping people explore and find things in collections. This isn’t about robots just doing all the work. It’s about extending and amplifying our ability to make materials available to users in ways that help them “get to the stuff.” Aside from that, there is a need to provide users with information on what actions were preformed on the collection to make it available. To that end, it’s exciting to realize that we can simply document what tools were used so that anyone can explore the potential biases of those tools in how they create interfaces to collection data.
So what does this all have to do with cyborgs and mecha? What is in some ways most interesting to me about topic modeling is that the topics themselves are actually somewhat arbitrary and meaningless. A topic in MALLET isn’t so much a topic in regular parlance as it is just a cluster of words that tend to appear together. It takes someone who knows the texts to make sense of those topics, to fiddle with the dials till they get topics that seem hang together right (in MALLET you pick how many topics you want it to look for). So Fondz will be far more useful when it integrates processes for archivists to exercise their expertise and their judgment and intervene. When they can name the topics and describe them. When they can accept or reject some of the topics, when they can rerun them.
Since the goal here is to make useful descriptions there is a potential here for topic modeling to be used instrumentally to surface connections for an archivist to find useful or not useful and to save the useful ones and describe them. Given that good processing is done with a shovel, not with a tweezers it is exciting to think about how tools like Fondz could integrate a range of techniques for computational analysis of the content of files to act as steam shovels; instruments that put the archivist in the driver’s seat to explore and work through relationships in collection materials and expose those to users.
There are a bunch of other cleaver things that Ed is doing with Fondz that warrant further discussion, but for the purpose of this post that does it. As far as take-away messages go, I’d suggest the following. The future of digital tools for digital archives is not about tools that “just work.” It’s not about replacing the work of archivists with automated processes, it’s about amplifying and extending the capabilities of an archivist to do cleaver things with somewhat blunt instruments (like topic modeling, NER, etc.) that make it easier for us to make materials accessible. Given that the nature of digital objects is a multiplicity of orders and arrangements, if we can generate a range of relatively quick and dirty points of entry to materials we can invest more time and energy in making sure that when someone gets down to the item they have breadcrumbs and information that situates and contextualizes the item in it’s collection and it’s custodial history. We need archival-mecha, tools that give archivists superpowers by amplifying their judgment, wisdom, knowledge, ethics and expertise in working with digital materials. We need to make sure we are getting the computers to do what computers do best in supporting the praxis of archival practice.

Leave a comment